¿Sabías que existen más de 700 lenguajes de programación? De hecho, algunas fuentes indican que incluso podrían existir… ¡cerca de 9000 lenguajes de programación! Aprenderlos todos sería imposible pero, por suerte, los más utilizados en la actualidad son solo 50, y entre ellos, se encuentra Python. ¿Quieres saber qué es Python, para qué sirve y por qué es uno de los lenguajes más demandados en el mundo del desarrollo de software? ¡Sigue leyendo!
¿Qué es y para qué sirve Python?
Python es un lenguaje de programación de alto nivel que se utiliza para desarrollar aplicaciones de todo tipo. A diferencia de otros lenguajes como Java o .NET, se trata de un lenguaje interpretado, es decir, que no es necesario compilarlo para ejecutar las aplicaciones escritas en Python, sino que se ejecutan directamente por el ordenador utilizando un programa denominado interpretador, por lo que no es necesario “traducirlo” a lenguaje máquina.
Python es un lenguaje sencillo de leer y escribir debido a su alta similitud con el lenguaje humano. Además, se trata de un lenguaje multiplataforma de código abierto y, por lo tanto, gratuito, lo que permite desarrollar software sin límites. Con el paso del tiempo, Python ha ido ganando adeptos gracias a su sencillez y a sus amplias posibilidades, sobre todo en los últimos años, ya que facilita trabajar con inteligencia artificial, big data, machine learning y data science, entre muchos otros campos en auge.
Para que puedas ver lo sencillo que es Python, a continuación tienes un simple programa escrito en este lenguaje, que podrás entender fácilmente incluso si no sabes nada de programación. Se trata de un pequeño aplicativo para calcular un sueldo por horas, algo muy sencillo pero que podría ser perfectamente funcional:
horas = float(input(«Introduce tus horas de trabajo: «))
coste = float(input(«Introduce lo que cobras por hora: «))
sueldo = horas * coste
print(«Tu sueldo es», sueldo)
En las dos primeras líneas se le pide al usuario que introduzca cuántas horas ha trabajado y lo que cobra por hora. En la tercera se hace la operación para calcular el sueldo total y se guarda en una variable. En la última línea de código se imprime por pantalla el resultado. Si, por ejemplo, ponemos que hemos trabajado 8 horas a 15 €, en pantalla se imprimirá “Tu sueldo es de 120”.
Origen de Python
Ahora que ya sabes qué es Python, puede que también quieras saber cómo surgió este increíble lenguaje de programación. A pesar de que pueda parecer algo muy nuevo, Python remonta su origen a principios de los años 90, cuando Guido Van Rossum, un trabajador del Centrum Wiskunde & Informatica (CWI), un centro de investigación holandés, tuvo la idea de desarrollar un nuevo lenguaje basándose en un proyecto anterior, el lenguaje de programación “ABC”, que él mismo había desarrollado junto a sus compañeros.
Su filosofía fue la misma desde el primer momento: crear un lenguaje de programación que fuera muy fácil de aprender, escribir y entender, sin que esto frenara su potencial para crear cualquier tipo de aplicación. En aquellos años, el hardware que había no permitía tal cosa, y es por eso por lo que Python ha resurgido durante los últimos años, porque el avance de la tecnología ha permitido alcanzar el objetivo inicial de este lenguaje de programación adelantado a su tiempo.
¿Dónde se utiliza Python?
Como ya has visto, Python es un lenguaje de programación multiplataforma, algo que permite desarrollar aplicaciones en cualquier sistema operativo con una facilidad asombrosa. Una gran cantidad de tecnologías se llevan muy bien con Python debido a su sencillez y a su gran potencia para el tratamiento de datos, algo que sin duda ha hecho resurgir este lenguaje a nivel laboral, donde cada vez son más las empresas que solicitan expertos en Python.
Data analytics y big data: El uso de Python está muy extendido en dos áreas que han estado, y estarán, en boca de todos: el análisis de datos y el big data. Su simplicidad y su gran número de bibliotecas de procesamiento de datos hacen que Python sea ideal a la hora de analizar y gestionar una gran cantidad de datos en tiempo real.
Python está siendo utilizado en la actualidad por muchísimas empresas, tanto de forma directa, como indirecta, ya que detrás de los distintos software de data analytics, muchas veces está este lenguaje interpretado de alto nivel. Analizar una gran cantidad de datos para transformarlos en información útil para el big data es una de las especialidades de Python.
Data mining: La minería de datos o data mining es un proceso que permite analizar grandes bases de datos con el objetivo de predecir futuras tendencias. Se trata de un proceso complejo al que Python puede arrojar luz a través de la limpieza y organización de datos y del uso de algoritmos de aprendizaje automático que simplifica el análisis de datos.
Data science: Tras la creación de los motores numéricos como “Pandas” o “NumPy”, Python está desbancando MATLAB, un lenguaje utilizado por científicos a la hora de trabajar con un gran número de datos. La razón es la misma que en los anteriores apartados; la sencillez y la potencia para trabajar con un gran número de datos, unidos al gran número de bibliotecas existentes, hacen que Python sea ideal para este tipo de tareas.
Inteligencia artificial: Seguro que durante los últimos años has oído hablar muchísimo de la inteligencia artificial (IA). Gran parte de su avance se debe a Python. Su facilidad de escritura y su robustez han convertido a Python en el aliado perfecto de la IA. Su capacidad de plasmar ideas complejas en pocas líneas, unidas al gran número de frameworks existentes, han hecho que Python sea uno de los lenguajes de programación que están impulsando a la IA.
Blockchain: La base de datos distribuida Blockchain, conocida mundialmente por ser la base sobre la que se sustentan las criptomonedas, también funciona muy bien junto a Python. Como lenguaje versátil, seguro y rápido, es muy útil para formar cadenas de bloques, e incluso permite a los desarrolladores crear una cadena de bloques sencilla en menos de 50 líneas de código, haciendo sencillo algo muy complejo.
Machine learning: El machine learningo aprendizaje automático es otra de las tecnologías que está cambiando el mundo tal y como lo conocemos. La robótica y la IA son ahora capaces de aprender por sí mismas a medida que van procesando más y más datos. De esta forma, obtienen información cada vez más relevante que les permite tomar las decisiones adecuadas. Por supuesto, Python es también muy eficaz en este campo, en el tratamiento de datos eficaz es esencial.
Desarrollo web: Python también permite desarrollar webs complejas en menos líneas de código, lo que permite que estas sean más ligeras y optimizadas. Django es uno de los frameworks de Python más populares de la actualidad, que puede ser utilizado para crear webs dinámicas y muy seguras. Python es también muy utilizado para hacer scraping, es decir, para obtener información de todo tipo de webs, tal y como lo hacen Netflix, Instagram o Pinterest.
Juegos y gráficos 3D: Python también posee una gran capacidad para manejar gráficos 3D gracias la gran cantidad de marcos de trabajo y herramientas existentes. PyGame, Blender o Arcade son algunos de los más conocidos. Uno de los juegos más populares desarrollado con Python es Battlefield 2, un juego de acción bélica lanzado en 2005 en el que el motor gráfico, las animaciones y sus distintas funcionalidades fueron desarrolladas con Python.
¿Por qué Python es uno de los lenguajes de programación más demandados en el mundo laboral?
Ahora que ya sabes qué es Python y para qué se utiliza, seguro que ya habrás deducido por qué es uno de los lenguajes de programación más demandados en el mundo laboral. Debido a su relación con algunos de los campos con mayor relevancia de la actualidad, como la IA, el Machine Learning o el análisis de datos, se necesitan un gran número de programadores expertos en Python para desarrollar nuevas y emocionantes funciones.
A pesar de que este lenguaje lleva 30 años en el mercado, las empresas se están encontrando con grandes dificultades para encontrar programadores con conocimientos avanzados de Python. Según el Informe de Empleos Emergentes 2020 de LinkedIn, la demanda de desarrolladores Python ha crecido un 48,73 % respecto al 2019. Los puestos de empleo, como no podía ser de otra forma, están relacionados con las tecnologías de la información (TIC), las telecomunicaciones y los servicios financieros.
Aprender Python y reorienta tu carrera laboral
Como has podido ver, Python es un lenguaje de programación de código abierto versátil, flexible, multiplataforma y totalmente gratuito, En el presente y en el futuro tendrá una gran relevancia debido a su utilidad en campos tecnológicos en auge como la inteligencia artificial, el big data, el data science, el machine learning, el Blockchain o el desarrollo web. Su uso va en aumento y, por lo tanto, la demanda de programadores expertos en Python, también.
¿Quieres aprender Python y reorientar tu carrera profesional? LasBecas Santander Tech | Reskilling in Data Analytics – Ubiqum Code Academy te ofrecen la oportunidad de hacerlo. Con el objetivo de mejorar la empleabilidad de los jóvenes, Banco Santander impulsa 200 becas para cursar un programa formativo de iniciación al análisis de datos.
Este curso se dividirá en 2 etapas, un curso inicial de Introducción al data analysis, donde podrás aprender a utilizar Python con tareas de minería de datos o aprendizaje automático, y una segunda etapa, reservada para los 50 mejores de la primera, que consistirá en un bootcamp de data analytics y machine learning en el que podrás profundizar en tus conocimientos con el objetivo de reorientar tu carrera laboral hacia el mundo de la economía digital. Este bootcamp tiene una duración de 6 meses, se realiza en la modalidad de part-time y está totalmente centrado en que puedas conseguir un empleo cualificado como programador. En él podrás aprender todo lo que necesitas para incorporarte al mundo laboral del desarrollo de software, utilizando metodologías innovadoras que apuestan por el learn by doing.
Vivimos en la era de la tecnología, pero aún no lo hemos visto todo: la computación cuántica, que en los últimos años ha dado pequeños —pero importantes— pasos de la mano de grandes empresas, promete revolucionar casi todo lo que conocemos. A continuación, repasamos sus posibles aplicaciones, que van desde la ciberseguridad a la movilidad pasando por la salud.
La computación cuántica está llamada a revolucionar la informática.
En un mundo binario de unos y ceros, los ordenadores cuánticos serían como los Albert Einstein de la informática, cerebros electrónicos extraordinarios capaces de realizar en unos segundos tareas casi imposibles para una computadora clásica.La multinacional IBM será la primera en comercializar uno de estos prodigios de la tecnología, el Q System One, un cubo de cristal de unos 3 x 3 metros y 20 qubits que fue presentado en 2019 y estará disponible para el ámbito empresarial y la investigación.
¿QUÉ ES LA COMPUTACIÓN CUÁNTICA?
Esta rama de la informática se basa en los principios de la superposición de la materia y el entrelazamiento cuántico para desarrollar una computación distinta a la tradicional. En teoría, sería capaz de almacenar muchísimos más estados por unidad de información y operar con algoritmos mucho más eficientes a nivel numérico, como el de Shor o el temple cuántico.
Esta nueva generación de superordenadores aprovecha el conocimiento de la mecánica cuántica —la parte de la física que estudia las partículas atómicas y subatómicas— para superar las limitaciones de la informática clásica. Aunque la computación cuántica presenta en la práctica problemas evidentes de escalabilidad y decoherencia, permite realizar multitud de operaciones simultáneas y eliminar el efecto túnel que afecta a la programación actual en la escala nanométrica.
¿QUÉ ES UN QUBIT?
La informática cuántica utiliza como unidad básica de información el qubit en lugar del bit convencional. La principal característica de este sistema alternativo es que admite la superposición coherente de unos y ceros,los dígitos del sistema binario sobre los que gira toda la computación, a diferencia del bit, que solo puede adoptar un valor al mismo tiempo —uno o cero—.
Esta particularidad de la tecnología cuántica hace que un qubit pueda ser cero y uno a la vez, y además en distinta proporción. La multiplicidad de estados posibilita que un ordenador cuántico de apenas 30 qubits, por ejemplo, pueda realizar 10 billones de operaciones en coma flotante por segundo, es decir, unos 5,8 billones más que la videoconsola PlayStation más potente del mercado.
DIFERENCIAS ENTRE LA COMPUTACIÓN CUÁNTICA Y LA TRADICIONAL
La computación cuántica y la tradicional son dos mundos paralelos con algunas similitudes y numerosas diferencias entre sí, como el uso del qubit frente al bit. A continuación, repasamos tres de las más relevantes:
Lenguaje de programación
La computación cuántica carece de un código propio para programar y recurre al desarrollo e implementación de algoritmos muy específicos. Sin embargo, la informática tradicional cuenta con lenguajes estandarizados como Java, SQL o Python, entre muchos otros.
Funcionalidad
Un ordenador cuántico no es una herramienta para uso popular ni cotidiano, como un ordenador personal (PC). Estas supercomputadoras son tan complejas que solo tienen cabida en el ámbito corporativo, científico y tecnológico.
Arquitectura
La composición de un ordenador cuántico es más sencilla que la de uno convencional, y no tiene memoria ni procesador. Estos equipos se limitan a un conjunto de qubits que sirven de base para su funcionamiento.
CONDICIONES DE FUNCIONAMIENTO DE UN ORDENADOR CUÁNTICO
Estos ordenadores son extremadamente sensibles y necesitan unas condiciones muy concretas de presión, temperatura y aislamiento para funcionar sin errores. La interacción de estas máquinas con partículas externas provoca fallos de medición y el borrado de las superposiciones de estados, de ahí que permanezcan selladas y se tengan que manejar a través de ordenadores convencionales.
Un ordenador cuántico necesita una presión atmosférica casi inexistente, una temperatura ambiente próxima al cero absoluto (-273 °C) y aislarse del campo magnético terrestre para evitar que los átomos se muevan y colisionen entre sí, o interactúen con el entorno. Además, estos sistemas funcionan durante intervalos muy cortos de tiempo, por lo que la información se termina dañando y no puede almacenarse, dificultando aún más la recuperación de los datos.
PRINCIPALES APLICACIONES DE LA COMPUTACIÓN CUÁNTICA
La seguridad informática, la biomedicina, el desarrollo de nuevos materiales y la economía son algunos de los ámbitos que podrían vivir una gran revolución gracias a los avances en computación cuántica. Estos son algunos de sus beneficios más interesantes:
Finanzas
Las empresas optimizarían aún más sus carteras de inversión y mejorarían los sistemas para la detección del fraude y la simulación.
Salud
Este sector se beneficiaría en el desarrollo de nuevos medicamentos y tratamientos personalizados genéticamente, así como en la investigación del ADN.
Ciberseguridad
La programación cuántica conlleva riesgos, pero también avances para la encriptación de datos,como el nuevo sistema Quantum Key Distribution (QKD). Esta nueva técnica para el envío de información sensible utiliza señales luminosas para detectar cualquier intromisión en el sistema.
Movilidad y transporte
Compañías como Airbus utilizan la computación cuántica para diseñar aviones más eficientes.Además, los qubits permitirán avances notables en los sistemas de planificación del tráfico y la optimización de rutas.
Si están pensando en aprender a programar en C++, te contamos los motivos por los que aprender C++ como lenguaje de programación. En este artículo vemos las ventajas y desventajas de este lenguaje tan versatil y comparaciones con otros lenguajes.
Ventajas de C++
Las ventajas que tiene C++ sobre otros lenguajes de programación son las siguientes:
Tiene un alto rendimiento.
Es un lenguaje que se está actualizando, y, por lo tanto, a pesar de tener más de 20 años es moderno.
Es multiplataforma.
Lenguaje de alto rendimiento
C++ tiene un alto rendimiento por varios motivos:
Permite hacer llamadas directamente al Sistema Operativo.
Es un lenguaje compilado para cada plataforma.
Tiene muchísimos parámetros de optimización.
Tiene un acceso directo a la memoria, que además controla el usuario.
Tiene una integración directa con el lenguaje ensamblador, tan directa que incluso permite escribir directamente en ensamblador con las diferentes directivas.
Lenguaje moderno y actualizado
C++ nos permite, entre otras muchas cosas:
Crear datos complejos.
Definir operaciones sobre los datos complejos.
Relacionar los datos complejos entre ellos.
Realizar programación genérica y templates, que es hacer una clase del mismo código que sirva para cualquier tipo que pase.
Implementar múltiples patrones de diseño
Comparativa con otros lenguajes
Podemos realizar una comparativa de C++ con otros conocidos lenguajes de programacion.
Se considera a C++ como un superset de C. De hecho, cuando Bjarne Stroustrup lo creó, comenzó a llamarlo “C con clases”, porque permitía hacer un paradigma de orientación a objetos, a diferencia de C, que no permite objetos.
Java y C# tienen una sintaxis muy parecida a C++, porque se quisieron basar en ella para que a los programadores no les costara mucho esfuerzo cambiarse de uno a otro. Funcionan sobre una máquina virtual, con los problemas de eficiencia que eso conlleva, pero también teniendo la ventaja de que no tienen hay que compilar el lenguaje para cada para cada sistema operativo, sino que funciona todo en su máquina virtual.
Rust es un lenguaje muy moderno que está surgiendo con fuerza y que está generando grandes expectativas, ya que tiene muchas cosas de programación funcional, al igual que C++, que con el nuevo estándar se está actualizando cada 3 años, y permite hacer programación funcional.
Haskell permite una mayor programación funcional que C++, ya que es un lenguaje de programación pura.
Scripting es un lenguaje interpretado, parecido a Java y C#, pero que no funciona sobre una máquina virtual sino sobre un proceso.
Ensamblador es un lenguaje muy difícil de controlar, muy difícil de programar, muy largo y tedioso, que para ello salieron los lenguajes de alto nivel.
Desventajas de C++
El uso de C++ tiene un coste:
Tiene que tener una compilación por plataforma.
Es un lenguaje muy amplio, ya que tiene muchos años y muchas líneas de código.
Su depuración es bastante complicada, debido a los errores que aparecen.
Resumen
A pesar de las desventajas, C++ es tan interesante porque permite programar en lenguaje de alto nivel, y en caso de necesitarlo, permite bajar incluso a lenguaje ensamblador.
Es decir, es un lenguaje que permite tanto alto, como bajo nivel de programación, para optimizar nuestro programa.
De los intentos realizados en este sentido se han llegado a definir las líneas fundamentales para la obtención de máquinas inteligentes: En un principio los esfuerzos estuvieron dirigidos a la obtención de autómatas, en el sentido de máquinas que realizaran, con más o menos éxito, alguna función típica de los seres humanos. En 1936 Alan Turing estudio el cerebro como una forma de ver el mundo de la computación. Sin embargo, los primeros teóricos que concibieron los fundamentos de la computación neuronal fueron Warren McCulloch un neurofisiólogo y Walter Pitts un matemático quienes en 1943 lanzaron una teoría acerca de la forma de trabajar de las neuronas. Ellos modelaron una red neuronal simple mediante circuitos eléctricos. Años más tarde en 1949 Donald Hebb escribió un importante libro en el que explicaba los procesos del aprendizaje desde un punto de vista psicológico, desarrollando una regla de como el aprendizaje ocurría. Su idea fue que el aprendizaje ocurría cuando ciertos cambios en una neurona eran activados. Los trabajos de Hebb formaron las bases de la Teoría de las Redes Neuronales. Luego en 1957 Frank Rosenblatt desarrolla el Perceptrón, Esta es la red neuronal más antigua utilizándose hoy en día para aplicación como reconocedor de patrones. Este modelo era capaz de generalizar, es decir, después de haber aprendido una serie de patrones podía reconocer otros similares, aunque no se le hubiesen presentado anteriormente. Sin embargo, tenía una serie de limitaciones, por ejemplo, su incapacidad para resolver el problema de la función OR-exclusiva y, en general, era incapaz de clasificar clases no separables linealmente. Diez años más tarde Stephen Grossberg realizó una red llamada Avalancha, que consistía en elementos discretos con actividad que varía en el tiempo que satisface ecuaciones diferenciales continuas, para resolver actividades como reconocimiento continúo de habla y aprendizaje de los brazos de un robot. En 1969 Marvin Minsky y Seymour Papert probaron (matemáticamente) que el Perceptrón no era capaz de resolver problemas relativamente fáciles, tales como el aprendizaje de una función no-lineal. Esto demostró que el Perceptrón era muy débil, dado que las funciones no-lineales son extensamente empleadas en computación y en los problemas del mundo real. Después de varios avances en 1980 Kunihiko Fukushima desarrolló un modelo neuronal para el reconocimiento de patrones visuales. Al instante en 1986 – David Rumelhart y G. Hinton redescubrieron el algoritmo de aprendizaje de propagación hacia atrás backpropagation. En la actualidad, las redes neuronales se componen de numerosas capas de procesamiento, en las cuales se emplean métodos para obtener modelos de representación de los datos de entrada, a través de módulos simples no lineales de representación, que se encargan de extraer las características y patrones de los datos en bruto y transferirlas a capas posteriores más abstractas. Esta forma de trabajar, dota a la red la capacidad de deducir por sí misma, la mejor manera de representar los datos, sin necesidad de haber sido programada explícitamente para ello. La forma más frecuente de aprendizaje automático, es el aprendizaje supervisado, en el cual el algoritmo requiere de una función objetivo, para ajustar los pesos de modo tal que las salidas del algoritmo se acerquen a la meta. De tal forma, las redes neuronales de aprendizaje supervisado, necesitan de una función objetivo, la cual es comparada con las salidas de la red, para calcular el valor de la función de costos, y así poder ajustar los pesos de las capas anteriores, de modo tal que en cada iteración se disminuya el error. Debido a que una red neuronal profunda puede tener millones de neuronas, y centenares de millones de conexiones (incluso miles de millones), resulta impráctico ajustar uno a uno los pesos, incluso se puede intentar calcular el error mediante un procedimiento analítico empleando derivadas, pero dado el elevado número de variables de la red el proceso sería extremadamente complicado. Es por eso que, el efecto de aprendizaje (reducción del error) se consigue empleando el método de gradiente descendente. Función de Activación Las funciones de activación son una idea tomada de la Biología y que trata de generalizar el hecho de que las neuronas biológicas no son sumadores y transmisores de impulsos, sino que tienen un mecanismo que decide si se activan o no, en función de la entrada que reciben. Es al activarse cuando envían una señal a través de su axón a otras neuronas que la siguen en la cadena de procesamiento. Que problemas solucionan las redes neuronales Optimización
Determinar una solución que sea óptima
Muy utilizado en la gestión empresarial (niveles adecuados de tesorería, de existencias, de producción)
Reconocimiento
Se entrena una Red Neuronal Artificial con entradas como sonidos, números, letras y se procede al test presentando esos mismos patrones con ruido.
Generalización
La Red Neuronal Artificial se entrena con unas entradas y el test se realiza con otros casos diferentes.
Clasificación
Asignar a cada caso su clase correspondiente (préstamos)
Predicción
Lo que más interés despierta (ratio)
Ejemplos
Conversión de texto escrito a lenguaje hablado.
Compresión de imágenes
Reconocimiento de escritura manual (japonesa)
Visión artificial en robots industriales (inspección de etiquetas, clasificación de componentes)
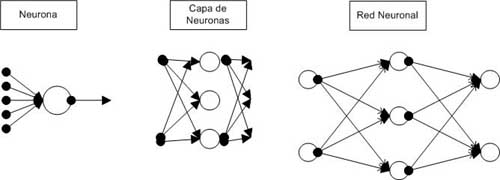
Clasificación respecto a la TopologíaLa topología o arquitectura de una red consiste en la organización y disposición de las neuronas en la red. Las neuronas se agrupan formando capas, que pueden tener muy distintas características. Además las capas se organizan para formar la estructura de la red. Se puede observar en la siguiente figura. La jerarquía de las redes neuronales :
Donde podemos ver que las neuronas se agrupan para formar capas y las capas se unen entre ellas formando redes neuronales. Para clasificar por la topología usaremos el número de capas en Redes Monocapas o Redes Multicapas. Redes Monocapas
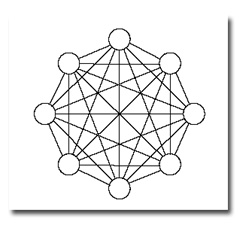
Las redes monocapa son redes con una sola capa, para unirse las neuronas crean conexiones laterales para conectar con otras neuronas de su capa. Las redes más representativas son la red de Hopfield, la red BRAIN-STATE-IN-A-BOX o memoria asociativa y las maquinas estocásticas de Botzmann y Cauchy.
Entre las redes neuronales monocapa, existen algunas que permiten que las neuronas tengan conexiones a si mismas y se denominan autorecurrentes.
Las redes monocapa han sido ampliamente utilizada en circuitos eléctricos ya que debido a su topología, son adecuadas para ser implementadas mediante hardware, usando matrices de diodos que representan las conexiones de las neuronas. Redes Multicapas Las redes multicapa están formadas por varias capas de neuronas (2,3…). Estas redes se pueden a su vez clasificar atendiendo a la manera en que se conexionan sus capas.
Usualmente, las capas están ordenadas por el orden en que reciben la señal desde la entrada hasta la salida y están unidas en ese orden. Ese tipo de conexiones se denominan conexiones feedforward o hacia delante.
Por el contrario existen algunas redes en que las capas aparte del orden normal algunas capas están también unidas desde la salida hasta la entrada en el orden inverso en que viajan las señales de información. Las conexiones de este tipo se llaman conexiones hacia atrás, feedback o retroalimentadas.
Redes con conexiones hacia adelante:
Como decíamos antes, Este tipo de redes contienen solo conexiones entre capas hacia delante. Esto implica que una capa no puede tener conexiones a una que reciba la señal antes que ella en la dinámica de la computación. Ejemplos de estas redes son Perceptron, Adaline, Madaline, Backpropagation y los modelos LQV y TMP de Kohonen. Redes con conexiones hacia atrás:
Este tipo de redes se diferencia en las anteriores en que si pueden existir conexiones de capas hacia atrás y por tanto la información puede regresar a capas anteriores en la dinámica de la red. Este Tipo de redes suelen ser bicapas. Ejemplos de estas redes son las redes ART, Bidirectional Associative Memory (BAM) y Cognitron.
La Interfaz gráfica de usuario o GUI (Graphic User Interface) es el entorno visual de imágenes y objetos mediante el cual una máquina y un usuario interactúan. A mediados de los setentas las GUI comenzaron a sustituir a las interfaces de línea de comando (CLI), y esto permitió que la interacción con las computadoras fuera más sencilla e intuitiva. Para ejemplificar de un modo más simple, veamos la diferencia entre una Interfaz de línea de comando y una Interfaz gráfica de usuario:
CLI Windows
GUI Windows
¿Para qué sirven las Interfaces gráficas de usuario?
Su función principal es simplificar la comunicación entre una máquina o un sistema operativo y un usuario. Antes de que se desarrollaran y popularizaron las GUI, solo las personas con conocimientos profundos de informática podían usar un computador, pero las interfaces gráficas sustituyeron la complejidad de los comandos por acciones predeterminadas simbolizadas por elementos visuales muy sencillos de comprender. A mediados de los ochentas, Mac se convirtió en el referente de las interfaces gráficas amigables desarrollando equipos con funciones muy complejas pero “tan fáciles de usar como una tostadora”, y por esas mismas fechas Microsoft lanzó Windows 1.0, un sistema operativo que se caracterizaba por tener una interfaz gráfica similar, lo que le valió una demanda millonaria de parte de Apple. Una buena GUI no solo es importante para los programas, sistemas operativos y aplicaciones. Se estima que el 68% de los visitantes que abandonan un sitio web lo hacen debido a que la experiencia de usuario, incluyendo la Interfaz, no está optimizada para sus necesidades y expectativas.
¿Cuáles son los elementos de la Interfaz gráfica de usuario?
Las interfaces gráficas de usuario integraron en sus inicios una novedad que hoy en día es de uso corriente: el mouse o ratón, que fungía como puntero para señalar y seleccionar los diferentes elementos de la GUI, que tradicionalmente se categorizaron como ventanas, iconos o carpetas. Hoy en día los elementos visuales de una interfaz son muy similares en esencia, sólo que cada día los diseñadores tratan de hacerlos más amigables e intuitivos. Además, los dispositivos móviles no requieren de ratón o puntero pues cuentan con pantallas táctiles.
¿Cómo crear una buena Interfaz gráfica de usuario?
Una buena GUI se caracteriza por:
Ser sencilla de comprender y usar
La curva de aprendizaje es acelerada y es fácil recordar su funcionamiento
Los elementos principales son muy identificables
Facilitar y predecir las acciones más comunes del usuario
La información está adecuadamente ordenada mediante menús, iconos, barras, etc.
Las operaciones son rápidas, intuitivas y reversibles
La interfaz expresa claramente el estado del sistema o las operaciones, y brinda elementos de ayuda.
La navegabilidad y la usabilidad son óptimas.
Características generales de la GUI:
Facilidad
Diseño ergonómico mediante el uso de menús, barras de acciones o íconos
Operaciones rápidas, reversibles; que sea de cambios inmediatos
Contiene herramientas de ayuda que orientan al usuario.
Para la realización de un buen desarrollo GUI, se debe tener en cuenta:
Consistencia: Todos los elementos de la GUI se deben regir por las mismas normas
Palabras y legibilidad: Uso de colores y fuentes adecuadas, uso correcto de mayúsculas y minúsculas
Color: Tener en cuenta el significado de los colores, que éstos permitan la legibilidad y que den una buena apariencia en la pantalla
Accesibilidad: Debe ser accesible en lo posible a todos teniendo en cuenta discapacidades
Necesidades de los usuarios: Los usuarios deben encontrar lo que buscan
Contenidos: Deben ser fiables
Funcionalidad: Debe reducir los pasos para la realización de una acción
Sistema de búsqueda: Debe contar con diferentes maneras de realizar la búsqueda
¿Quiénes son responsables de la Interfaz gráfica de usuario?
Detrás de cualquier Interfaz gráfica de usuario existe un programa, sistema operativo o aplicación. Por eso, la GUI suele ser un trabajo en conjunto entre desarrolladores y diseñadores que buscan la mejor manera de que el usuario pueda interactuar con el programa mediante elementos visuales fáciles de comprender.
La aplicación de IA en los procesos de las actividades productivas y de servicios representará un salto cualitativo en el crecimiento de las economías nacionales y supranacionales. En este sentido, debe diseñarse de qué manera las instituciones pueden ayudar a las empresas, grandes y pequeñas, a utilizar estas herramientas y competir en un mundo global, facilitando la investigación, la innovación y la explotación de la IA.
Ámbito educativo.
Es necesario abordar nuevas fórmulas educativas para el conjunto de la sociedad, especialmente para las nuevas generaciones. La ciudadanía debe entender el funcionamiento de los procesos algorítmicos para poder comprender su interrelación diaria con la IA y poder tomar decisiones informadas. Además, es importante considerar aproximaciones educativas a la IA no meramente desde el campo técnico, sino también desde las ciencias sociales, políticas o económicas, las humanidades, las artes, etc.
Ámbito laboral
Uno de los grandes interrogantes de este proceso es el grado de automatización de los procesos productivos. La robotización creciente no sólo afecta al sector industrial, también al de los servicios. Deben asegurarse herramientas para garantizar una transición en el mercado de trabajo que pueda cubrir la demanda de fuerza laboral procedente de sectores automatizados.
Ámbito legal
La proliferación de sistemas autónomos o semiautónomos, dirigidos por algoritmos de IA, como es el caso de los coches autónomos, provoca dudas sobre la determinación de la responsabilidad en caso de que los resultados sean dañinos o infrinjan las normas. Cuestiones como quién es responsable de efectos indeseados en una operación algorítmica (el diseñador, el propietario del algorítmico o la empresa que lo aplica a su negocio) deben determinarse para asegurar la seguridad de la apuesta por la IA.
Ámbito político y democrático
Las plataformas digitales se convirtieron en infraestructuras públicas donde la ciudadanía se informa, opina y decide respecto a debates públicos e institucionales. Las técnicas de IA demostraron ser una herramienta poderosa para modificar el curso de acontecimientos políticos como, por ejemplo, referéndums o elecciones. Las sociedades deben prestar especial atención al efecto público de contenidos automatizados que pueden ser, cada vez más, modificados o incluso creados por algoritmos.
Ámbito social
Parte del desarrollo acelerado de la IA en los últimos años es debido a la proliferación de servicios digitales utilizados por miles de millones de personas. La ciudadanía, a través de su actividad, es generadora de grandes cantidades de datos sobre su actividad, sus gustos, patrones de vida, sus relaciones, opiniones y sentimientos. Con todo, existe un desconocimiento profundo por parte de esta ciudadanía sobre cómo funcionan estos sistemas y de la utilización que se hace de sus datos, convirtiéndolos a menudo en consumidores y generadores de esta tecnología sin pleno conocimiento
Primero que nada nos vamos a ir a la terminal de Linux, para hacer esto podemos ingresar mediante Alt+Ctrl+T. Una vez dentro la forma más básica de comenzar a programar c/c++ es hacerlo mediante terminal. Esto principlamente por que aislamos todos los parámetros que se necesitan para programar, en otros programas donde se usa IDE o Compiadores extras se pierde un poco de información y la noción de lo que se esta haceindo pierde un poco de esencia.
Terminal en Lubuntu
Terminal de Linux
Vamos a comenzar con abrir la terminal y posicionarnos en la carpeta de trabajo, en este caso podemos crear una carpeta en el escritorio.
$ mkdir Desktop/Ejemplos
En la carpeta vamos a crear otra carpeta para el primer ejemplo
$ cd Desktop/Ejemplos $ mkdir EJ01
Posteriormente vamos a crear un nuevo archivo de texto para poder comenzar a programar, este lo vamos a crear con extensión cpp. Vamos a utilizar el editor nano de la terminal.
$ nano ejemplo01.cpp
Aparecerá posteriormente un editor de texto en la terminal que nos servirá para escribir nuestro programa.
Primer ejemplo en c/c++
Vamos a comenzar a escribir un programa en lenguaje c/c++ lo más básico seria escribir Hola Mundo en la terminal, para esto vamos a ver qué es lo que necesitamos.
Primero que nada vamos a llamar la biblioteca principal iostream (cubriremos más información de esta biblioteca más adelante). Posteriormente creamos la función main. Por lo que el cuerpo principal del programa nos quedaría como sigue:
#include<iostream> int main (void){ }
Ahora, para poder imprimir información necesitamos mandar llamar la instrucción para imprimir en terminal “cout”, la misma instrucción requiere un espacio de nombres (mas adelante veremos el espacio de nombres mas a detalle), en este caso el espacio de nombres seria “std” por lo que necesitamos poner la siguiente instrucción.
using namespace std;
Por ultimo mandamos llamar (ahora que tenemos el espacio de nombres adecuado) la instrucción “cout”.
cout << “Hola Mundo HeTPro” << endl;
El programa nos quedaría de la siguiente manera:
#include<iostream> using namespace std; int main (void){ cout << “Hola Mundo HeTpro” << endl; return 0; }
Ahora podemos guarder el codigo con Ctrl+x y seleccionando que si se quieren guardar cambios.
Compilar con g++ en c/c++ y ejecutar el codigo
Una vez de regreso en la terminal y lo que procede a continuación es compliar el código. Para poder compilar el código vamos a utilizar g++ que es el compilador libre por defecto de Linux, para este caso vamos a utilizar la siguiente instrucción:
En donde g++ es como ya se había mencionado anteriormente, el compilador, -Wall activa las banderas para visualizar warnings o errores –o es para generar el objeto, <nombre del ejecutable> es el archivo que se va a generar y <nombre del archivo a compilar> es el archivo que acabamos de escribir, por lo que en este caso nos quedaría como se muestra a continuación
g++ -Wall –o Ejemplo ejemplo01.cpp
Si nos marca algún error o warning tendríamos que revisar y buscar que esta generando el error, aunque si el código se escribió correctamente no debería de mostrar nada. Si la compilación se realiza de manera exitosa podemos ver con el comando “ls” en terminal que se ah generado un nuevo archivo que se llama “Ejemplo”. Para poder correr el archivo “Ejemplo” en nuestra terminal escribimos en la misma:
En este tutorial aprenderemos a usar la propiedad de la herencia de clases de Java mediante el pequeño ejemplo de una calculadora.
¿Qué es la herencia de clases?
La herencia de clases es la posibilidad de una clase de poder usar los atributos y métodos que ya existen en otra clase distinta, en la Programación Orientada a Objetos (POO) se hace heredando de la clase que contengan los elementos necesarios para tal fin.
La herencia está fuertemente ligada a la reutilización del código en la POO. Esto es, el código de cualquiera de las clases puede ser utilizado sin más que crear una clase derivada de ella, o bien una subclase.
Para poder entender mejor estos conceptos veremos un ejemplo sencillo como lo es el desarrollo de una calculadora con las 4 operaciones básicas (suma, resta, multiplicación y división). Para empezar vamos a definir nuestras clases a usar.
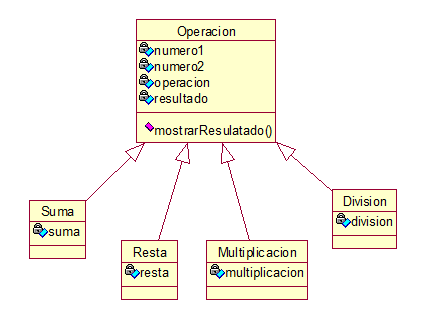
Como podemos observar todas las clases tienen tanto atributos como métodos iguales, esto es perfecto para usar herencia, definimos una nueva clase que contenga todos los atributos y métodos de nuestras 4 clases, a esta nueva clase la llamaremos operación y tendríamos ahora el siguiente esquema:
Como podemos observar ahora tenemos la clase Operacion la cual es una superClase porque contiene atributos y métodos que serán heredados por otras clases, y las clases Suma, Resta, Multiplicacion y division que son las subClases porque heredan atributos y métodos de la superClase Operacion.
Ahora que ya entendimos lo que es herencia vamos a implementarla, para este tutorial vamos a trabajar con el lenguaje de programación Java y el entorno de desarrollo NetBeans.
Primero implementaremos la superClase Operacion que es la que contiene los atributos y métodos a heredar
La herencia en Java (y en otros lenguajes de programación) se declara con la palabra reservada extends seguida de la clase de la cual deseamos heredar.
Para la clase Suma quedaría así:
public class Suma extends Operacion{ double suma; public Suma(double n1, double n2) { super(n1, n2, '+'); this.suma = n1 + n2; this.setRes(this.suma); } }
Resta:
public class Resta extends Operacion{ double resta; public Resta(double n1, double n2) { super(n1, n2, '-'); this.resta = n1 - n2; this.setRes(this.resta); } }
Multiplicación:
public class Multiplicacion extends Operacion{ double multi; public Multiplicacion(double n1, double n2) { super(n1, n2, '*'); this.multi = n1 * n2; this.setRes(this.multi); } }
y por último División:
public class Division extends Operacion{ double div = 0; public Division(double n1, double n2) { super(n1, n2, '/'); if(n2==0) System.out.println("No se puede dividir entre cero"); else this.div = n1 / n2; this.setRes(this.div); } }
Como podemos apreciar en las cuatro clases utilizamos la palabra reservada extends y seguida la clase de la cual se está heredando en nuestro caso Operacion, esto permite tener acceso a los métodos y atributos de esta clase, además hacemos uso del método super que hace una instancia de la superClase Operacion enviando como parámetros los números con los cuales se realizará la operación y el símbolo de esta, luego ejecutamos la operación y enviamos el resultado a la superClase.
En nuestro programa principal instanciamos a cada una de las clases para realizar las operaciones y hacemos uso del método de la superClase Operacion para mostrar los resultados.
double n1 = 10; double n2 = 5; //suma Suma sum = new Suma(n1,n2); sum.mostrarResultado(); //resta Resta res = new Resta(n1,n2); res.mostrarResultado(); //multiplicacion Multiplicacion mul = new Multiplicacion(n1,n2); mul.mostrarResultado(); //division Division div = new Division(n1,n2); div.mostrarResultado();
Como resultado obtenemos el resultado de las operaciones y las podemos observar en la consola de salida de NetBeans, así que la herencia funciona correctamente.
Un autómata es cualquier mecanismo capaz de realizar un trabajo de forma autónoma (un reloj, una caja de música, la cisterna del WC, un radiador con termostato).
Todos estos aparatos tienen en común que, una vez conectados, pueden realizar su función sin más intervención externa. También comparten el hecho de que son bastante simples. Unos autómatas más flexibles serían un organillo, un video, una lavadora, ya que al menos su repertorio de acciones posibles es más variado. El ejemplo del organillo es revelador ya que en él aparecen las mismas fases que en el desarollo de un programa: una pieza de música es «diseñada» por un composistor, codificada en un soporte físico y ejecutada por una máquina.
En estor términos, un ordenador es un autómata de cálculo gobernado por un programa, de tal modo que diferentes programas harán trabajar al ordenador de distinta forma. Un programa es la codificación de un algoritmo, y un algoritmo es la descripción precisa de una sucesión de instrucciones que permiten llevar a cabo un trabajo en un número finito de pasos.
Así, un ordenador es probablemente el más flexible de los autómatas, ya que la tarea a ejecutar puede ser descrita por cualquier algoritmo que el usuario esté dispuesto a codificar.
Computadora: dispositivo electrónico programable que puede almacenar, recuperar y procesar datos.
Programar: planificar una secuencia de instrucciones que ha de seguir una computadora.
Programa: la secuencia de instrucciones.
Lenguaje de programación: conjunto de reglas, símbolos y palabras especiales utilizadas para construir programas.
Los ordenadores nos permiten hacer tareas más eficiente y rápida y con más precisión de lo que seríamos capaces de conseguir a mano, en el caso de que pudieramos hacerlas a mano.
Para utilizar esta herramienta, debemos especificar exactamente lo que queremos hacer y el orden en el que debe hacerse. Esto se hace mediante la programación, y por ello nos interesa aprender a programar.
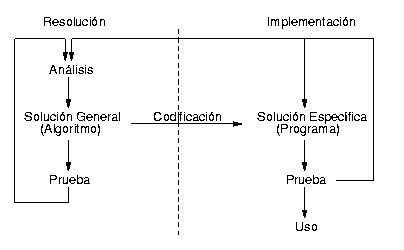
Para escribir una secuencia de instrucciones que ha de seguir una computadora, debemos seguir cierto procedimiento compuesto de una fase de resolución del problema y de una fase de implementación:
Fase de resolución del problema:
Análisis: Comprender y definir el problema.
Solución General (algoritmo): Desarrollar una secuencia lógica de pasos que conducirá a la solución del problema.
Prueba: Seguir los pasos exactos descritos en el algoritmo para ver si la solución propuesta resuelve verdaderamente el problema.
Fase de implementación:
Solución específica (programa): Traducir el algoritmo a un lenguaje de programación dado.
Prueba: Hacer que la computadora siga las instrucciones, comprobando el resultado, y haciendo las correcciones precisas hasta que las respuestas sean correctas.
Uso: Utilización del programa.
La documentación y el mantenimiento también son partes de la programación, y las veremos a lo largo del discurso de la materia.
1.2 Algoritmo
El origen de la palabra se piensa que es el nombre de un algebrista árabe llamado Mûsâ al-Khowârizmî, AD 825.
Un algoritmo es un procedimiento especificado paso a paso para resolver un problema en una cantidad finita de tiempo.
Finitud: debe terminar tras un número finito de etapas.
Definición: cada paso debe estar definido con precisión, siendo riguroso y sin ambiguedad.
Entrada: tendrá 0 o más entradas, informaciones que se proporcionan al algoritmo antes de funcionar.
Salida: tendrá 1 o más salidas, y guardarán una relación con las entradas.
Efectividad: debe poder especificarse en función de operaciones realizables, no fantasiosas.
Por ejemplo está el algoritmo de cambiar una rueda pinchada en un automovil:
Quitar la rueda.
Aflojar los tornillos.
Levantar el automovil.
Extraer la rueda.
Retirar los tornillos.
Retirar la rueda.
Poner la rueda.
Colocar la rueda.
Presentar la rueda.
Poner los tornillos.
Bajar el coche.
Apretar los tornillos.
En el algoritmo anterior muchos de los pasos son demasiado vagos para ser considerados bien definidos; de modo que habría que concretarlos más.
Los algoritmos se suelen expresar utilizando una manera mas o menos formal de lenguaje, llamado pseudocódigo, que toma diversas formas, alguna de ellas más gráficas, y otras más cercanas al lenguaje humano.
Los primeros algoritmos conocidos están fechados entre los años 3000 y 1500 AC. Fueron encontrados en la zona conocida como Mesopotamia (actualmente Irak) cerca de la ciudad de Babilonia. Estos algoritmos no tenían ni condicionales (los expresaban escibiendo varias veces el algoritmo) ni iteraciones (extendían el algoritmo con tantos pasos como fuera necesario). Problablemente más conocido, es el matemático griego Euclides, que hacia el año 300 AC., definió un algoritmo para calcular el máximo común divisor de dos enteros positivos. Aunque en este algoritmo se incluía la iteración, presentaba pocas mejoras respecto a los anteriores.
El algoritmo de Euclides trabaja con dos enteros m y n com m>n>0 y se describe como sigue:
mientras m > 0 hacer
t = n mod m
n = m
m = t
devolver n
Más recientes fueron las aportaciones en esta campo de Charles Babbage, quien entre los años 1820 y 1850, diseñó dos máquinas para computar ninguna de las cuales fue terminada. La más interesante, ya que se parecía a los computadores digitales modernos, fue la máquina analítica. Los programas para este primer computador estaban escritos, básicamente, en lenguaje máquina y utilizaban unas ciertas tarjetas de operación y tarjetas de datos. Junto a Babbage trabajó Ada Augusta, condesa de Lovelace, hija del famoso poeta Lord Byron, que recientemente ha sido reconocida como la primera programadora y en su honor se llamó ADA al último lenguaje desarrollado bajo el auspicio del Dpto. de Defensa de los USA.
Durante los años 30 y 40 surge un gran número de gente con ideas sobre notaciones para la programación. La mayoría eran puramente teóricas. Algunos ejemplos son la máquina de Turing o el cálculo Lambda.
A principios de los años 50 se empezaron a construir máquinas con cierta capacidad de cálculo (aunque muy limitadas y costosas), que trabajaban con lenguajes de tipo ensamblador.
1.3 Evolución de los lenguajes
Los métodos de diseño e implementación de los lenguajes de programación han evolucionado rápidamente desde los primeros lenguajes de alto nivel que aparecieron a principios de los años 30.
1.3.1 Perspectiva histórica
Comenzaremos por seguir el desarrollo histórico de los lenguajes de programación actuales.
Las primeras generaciones
Antes de que un computador pueda ejecutar una tarea, debe programársele para que lo haga colocando en la memoria principal un algoritmo apropiado, expresado en lenguaje máquina, que no es más que una secuencia de números mediante los que se representan las operaciones a realizar y los operandos con los que operar. Originariamente, este proceso de programación se realizaba por el laborioso método de expresar todos los algoritmos en el lenguaje de máquina, enfoque que hacía más penosa la ya de por sí difícil tarea de diseñar un programa, y en la mayoría de los casos daba pie a errores que era necesario localizar y corregir.
El primer paso para eliminar estas complejidades del proceso de programación fue la asignación de nombres mnemónicos a los diversos códigos de operación, y usarlos en vez de la representación hexadecimal, aumentando considerablemente la comprensibilidad de las secuencias de instrucciones de la máquina. Luego un programa especial llamado ensamblador se encargaba la traducción de los códigos mnémonicos a instrucciones en lenguaje máquina. A estos programas se les llamó ensambladores, pues su tarea era ensamblar instrucciones en lenguaje máquina a partir de códigos de operación y operandos. Por extensión, a los lenguajes que utilizaban los mnemónicos se les llamó lenguajes ensamblador.
En la época en que aparecieron los primeros lenguajes ensambladores, parecía que se había dado un gigantesco salto hacia adelante en la búsqueda de mejores entornos de programación, y es por ello que se les comenzó a llamar lenguajes de segunda generación, siendo la primera generación la compuesta por los lenguajes máquina. Estamos en los primeros años 50 y ejemplos de estos lenguajes podrían ser AUTOCODER, SPS, BAL o EASYCODER.
Una consecuencia importante de la íntima asociación entre los lenguajes ensambalador y de máquina es que cualquier programa escrito en lenguaje ensamblador depende inherentemente de la máquina; esto es, las instrucciones del programa se expresan en términos de los atributos de una máquina específica. Por tanto, un programa escrito en lenguaje ensamblador no se puede transportar fácilmente a otra máquina porque se tiene que reescribir de modo que se ajuste a la configuración de registros y al conjunto de instrucciones de la nueva máquina.
Otra desventaja de los lenguajes ensambladores es que el programador, aunque no tiene que codificar las intrucciones en forma de patrones de bits, sí está obligado a pensar en térnimos de los pequeños pasos incrementales del lenguaje de la máquina, y no puede concentrarse en la solución global de la tarea que está realizando. En pocas palabras, las instrucciones elementales en que se debe expresar finalmente un programa no son necesariamente las instrucciones que deben usarse al diseñarlo.
La tercera generación
De acuerdo con esta idea, a mediados de los 50 se comenzaron a crear lenguajes de programación que eran más propicios para la elaboración de software que los lenguajes ensamblador de bajo nivel. El resultado fue la aparición de una tercera generación de lenguajes de programación que difería de las anteriores en que sus instrucciones eran de alto nivel y además independientes de las máquinas. Una vez escrito el programa con instrucciones de alto nivel, se utilizaba un programa llamado traductor que traducía a lenguaje máquina los programas escritos en lenguajes de alto nivel. Estos programas son parecidos a los ensambladores de la segunda generación, solo que a menudo tienen que compliar, reunir varias instrucciones de máquina para formar secuencias cortas que simularan la actividad solicitada por la instrucción de alto nivel, y por esta razón se comenzó a llamar compiladores a este tipo de programa.
Unos de los primeros lenguajes de la tercera generación son FORTRAN y COBOL, por lo que algunas clasificaciones les colocan en la segunda generación. También está ALGOL60. Después de estos aparecen otros como BASIC (1965), SNOBOL, APL, PL/1 y SIMULA, entre otros. En los 70 aparecen lenguajes de alto nivel como PASCAL, C, MODULA y PROLOG. Más recientes son Eiffel, Smalltalk, ADA, ML, C++ y Java.
Con la aparición de los lenguajes de tercera generación se alcanzó, en gran medida la meta de la independiencia respecto a las máquinas. Como las instrucciones de estos lenguajes no hacían referencia a los atributos de ninguna máquina en particular, se podían compilar con la misma facilidad en una u otras máquinas. Así, en teoría, un programa escrito en un lenguaje de tercera generación se podía utilizar en cualquier máquina con sólo aplicar el compilador apropiado. Sin embargo, la realidad no ha resultado ser tan simple.
Las tres primeras generaciones de lenguajes siguen una sucesión en el tiempo, mientras que a partir de ahí, las dos últimas generaciones han evolucionado paralelamente y en campos bastantes distintos.
La cuarta generación
Los lenguajes de cuarta generación pretenden superar los problemas surgidos de los lenguajes de tercera generación:
Acelerar el proceso de construcción de aplicaciones.
Hacer aplicaciones fáciles y rápidas de modificar, reduciendo por tanto los costes de mantenimiento.
Minimizar los problemas de búsqueda y corrección de errores.
Generar código ejecutable sin errores a partir de los requerimientos deseados, dados con expresiones de alto nivel.
Hacer lenguajes fáciles de usar, de manera que el usuario final pueda resolver sus propios problemas usando él mismo el lenguaje de programación.
Estos lenguajes permiten generar aplicaciones de cierta complejidad con un número de líneas menor que el que tendríamos si usáramos un lenguaje de tercera generación. Para construir aplicaciones el programador contará, aparte de un conjunto de instrucciones secuenciales, con una gran diversidad de mecanismos como son: el rellenado de formularios, la interacción con la pantalla, etc. Un ejemplo de este tipo de lenguajes es SQL.
La quinta generación
La quinta generación de lenguajes se ha relacionado con los lenguajes que se utilizan en el campo de la inteligencia artificial: sistemas basados en el conocimiento, sistemas expertos, mecanismos de inferencia o procesamiento del lenguaje natual. Lenguajes como LISP o PROLOG han sido la base de este tipo de lenguajes.
1.4 Lenguajes Orientado al Objeto
Vamos a centrar nuestro estudio en un lenguaje orientado a objetos, y antes de ver las características de este tipo de lenguajes es bueno dar un repaso de los diferentes tipos de lenguajes de programación que han existido.
1.4.1 Clasificación de los lenguajes
Aunque existan cientos de lenguajes diferentes, estos se pueden agrupar segun las distintas filosofías que han seguido y la forma de trabajar que implican.
Lenguajes procedimentales
El paradigma por procedimientos, también conocido como paradigma imperativo, representa el enfoque tradicional del proceso de programación. Se define el proceso de programación como el desarrollo de procedimientos que, al seguirse, manipulan los datos para producir el resultado deseado. Así, el paradigma por procedimientos nos dice que abordemos un problema tratando de hallar un método para resolverlo.
Lenguajes declarativos
En contraste, consideremos el paradigma declarativo que hace hincapié en la pregunta ¿Cuál es el problema? en vez de ¿Qué procedimiento necesitamos para resolver el problema?. Lo importante aquí es descubrir e implantar un algoritmo general para la resolución de problemas, después de lo cual se podrán resolver éstos con sólo expresarlos en una forma compatible con dicho algoritmo y aplicarlo. En este contexto, la tarea del programador se reduce a crear un enunciado preciso del problema, más que a descubrir un algoritmo para resolverlo.
Desde luego, el principal obstáculo para crear un lenguaje de programación basado en el paradigma declarativo es el descubrimiento del algorimo básico para resolver problemas. Por esta razón, los lenguajes declarativos tienden a ser de propósito específico, diseñados para usarse en aplicaciones particulares.
Lenguajes funcionales
El paradigma funcional contempla el proceso de creación de programas como la construcción de cajas negras, cada una de las cuales acepta entradas y produce salidas. Los matemáticos llaman funciones a tales cajas, y es por ello que este enfoque se denomina paradigma funcional. Las primitivas de un lenguaje de programación funcional consisten en funciones elementales a partir de las cuales el programador debe construir las funciones más elaboradas necesarias para resolver el problema en cuestión.
1.4.2 Lenguajes Orientados al Objeto
Otro enfoque para la creación de programas es el paradigma orientado a objetos, OO. El término programación orientada a objetos se refiere a un estilo de programación por lo que un lenguaje orientado a objetos puede ser tanto imperativo como declarativo; lo que los caracteriza es la forma de manejar la información: clase, objeto y herencia. En este enfoque, las unidades de datos se consideran objetos activos, en vez de las unidades pasivas contempladas por el paradigma por procedimientos tradicional. Para aclarar esto, consideremos una lista de nombres. En el paradigma por procedimientos, esta lista no es más que una colección de datos, y cualquier programa que quiera trabajar con ella deberá incluir los algoritmos para realizar las manipulaciones requeridas. Así, la lista es pasiva en el sentido de que la mantiene un programa controlador, en vez de tener la responsabilidad de mantenerse ella misma. En cambio, en el enfoque orientado a objetos la lista se considera como un objeto formado por la lista misma y por una serie de rutinas para manipularla. Por ejemplo, pueden ser rutinas para insertar una nueva entrada en la lista, para detectar si la lista está vacía o para ordenar la lista. De este modo, un programa que obtiene acceso a esta lista no necesita contener algoritmos para efectuar esas tareas; simplemente aprovecha las rutinas suministradas en el objeto. En cierto sentido, en vez de ordenar la lista como en el paradigma por procedimientos, el programa pide a la lista que se ordene a sí misma.
Muchas ventajas del paradigma orientado a objetos son consecuencias de la estructura modular que surge como subproducto natural de la filosofía orientada a objetos, pues cada objeto se implanta como un módulo individual, bien definido, cuyas características son en gran medida independientes del resto del sistema. Así, una vez desarrollado un objeto que representa a una determinada entidad, es posible reutilizar ese objeto cada vez que se requiera dicha entidad. De hecho, un rasgo primoridal de los lenguajes de programación orientados a objetos es la capacidad de representar definiciones de objetos a modo de esqueletos, clases, que pueden usarse una y otra vez para construir múltiples objetos con las mismas propiedades, herencia, o modificarse para construir nuevos objetos con propiedades similares.
La programación OO está adquiriendo popularidad a grandes pasos, y muchos creen que dominará el campo de la programación en el futuro.
El lenguaje orientado a objetos más conocido es Smalltalk, que apareció en 1976. Es un lenguaje de tipo imperativo donde se utilizó por primera vez el vocabulario que se ha hecho característico de este tipo de lenguajes. Un lenguaje que se ha añadido a los llamados orientados a objetos es la extensión de C aparecida en 1986, C++. Aunque es muy diferente a Smalltalk, ha sido muy popular por ser una extensión del lenguaje C. Uno de los últimos lenguajes OO aparecidos es Java, al que dedicamos el siguiente apartado.
1.5 El lenguaje de programación Java
Java es una tecnología que hace sencilla la construcción de aplicaciones distribuidas, programas que son ejecutables por múltiples ordenadores a través de la red. En el estado del arte en la programación de red, Java promete extender el papel de Internet desde el terreno de las comunicaciones hacia una red en la cual puedan ejecutarse las aplicaciones completas. Su novedosa tecnología permitirá a los negocios proporcionar servicios de transacción a gran escala y en tiempo real y contener informacion interactiva en Internet. Java simplifica también la construcción de agentes software, programas que se mueven a través de la red y desempeñan funciones en ordenadores remotos en nombre del usuario. En un futuro cercano, los usuarios podrán enviar agentes software desde sus PCs hacia Internet para localizar información específica o para realizar transacciones en el menor tiempo posible en cualquier lugar del mundo.
Java llevará estos adelantos todavía más lejos haciendo posible suministrar aplicaciones completamente interactivas vía Web. Las razones por las cuales se ha prestado tanta atención al lenguaje Java podrían resumirse en la siguiente lista de posibilidades que Java ofrece a sus usuarios:
Escribir programas fiables y robustos.
Construir una aplicación para prácticamente cualquier plataforma, y ejecutar dicha aplicación en cualquier otra plataforma soportada sin tener que repetir la compilación del código.
Distribuir sus aplicaciones a lo largo de la red de una forma segura.
En particular, los programas Java se pueden incrustar en documentos Web, convirtiendo páginas estáticas en aplicaciones que se ejecutan en el ordenador del usuario.
1.5.1 Una Breve Historia sobre Java
En 1990, Sun Microsystems comenzó un proyecto llamado Green para desarrollar software destinado a electrónica de consumo. James Gosling, un veterano en el diseño de software de red, fue asignado al nuevo proyecto. Gosling comenzó a escribir software en C++ para utilizarlo en aparatos como tostadoras, videos, etc. Este software se utilizó para crear electrodomésticos más inteligentes, añadiéndoles displays digitales o utilizando inteligencia artificial para controlar mejor los mecanismos. Sin embargo, pronto se dio cuenta de que C++ era demasiado susceptible a errores que pueden detener el sistema. Y aunque todo el mundo está acostumbrado a que el ordenador se cuelgue, nadie espera que su tostadora deje de funcionar.
La solución de Gosling a este problema fue un nuevo lenguaje llamado Oak. Oak mantuvo una sintaxis similar a C++ pero omitiendo las características potencialmente peligrosas. Para conseguir que fuese un lenguaje de programación de sistemas controladores eficiente, Oak necesitaba poder responder a eventos provenientes del exterior en cuestión de microsegundos. Tambén era necesario que fuese portátil; esto es, que fuese capaz de ejecutarse en un determinado número de chips y entornos diferentes. Esta independencia del hardware podría proporcionar al fabricante de una tostadora cambiar el chip que utiliza para hacerla funcionar sin necesidad de cambiar el software. El fabricante podría utilizar también partes del mismo código que utiliza la tostadora para hacer funcionar un horno. Esto podría reducir costes, tanto de desarrollo como de hardware, aumentando también su fiabilidad.
Al mismo tiempo que Oak maduraba, la WWW se encontraba en su periodo de crecimiento y el equipo de desarrollo de Sun se dio cuenta de que Oak era prefectamente adecuado para la programación en Internet. En 1994 completaron su trabajo en un producto conocido como WebRunner, un primitivo visor Web escrito en Oak. WebRunner se renombró posteriomente como HotJava y demostró el poder de Oak como herramienta de desarrollo en Internet.
Finalmente, en 1995, Oak se renombró como Java por razones de marketing y fue presentado en Sun World 1995. Incluso antes de la primera distribución del compilador de Java en Junio de 1996, Java ya era considerado como el estándar en la industria para la programación en Internet.
1.5.2 La Arquitectura Java
La fortaleza de Java reside precisamente en su arquitectura única. Los diseñadores de Java necesitaban un lenguaje que fuera, sobre todo, sencillo de utilizar para el programador. A pesar de todo, y con el propósito de crear aplicaciones de red eficientes, Java necesitaba también la posibilidad de ejecutarse de forma segura en la red y trabajar en una amplísima gama de plataformas. Java cumple todos estos puntos y muchos más.
Cómo trabaja Java
Como muchos otros lenguajes de programación, Java utiliza un compilador para convertir el código fuente, legible para el ser humano, en programas ejecutables. Los compiladores tradicionales genera código que puede ejecutarse únicamente por un hardware específico. Los compiladores Java generan código binario o bytecode independiente de la arquitectura. Estos bytecodes se ejecutarán exclusivamente en una Máquina Virtual Java, Virtual Machine, VM, un procesador Java idealizado que normalmente se implementa por software, aunque la VM se ha implementado también como un chip hardware por Sun y otros.
Los archivos binarios Java se denominan archivos de clases debido a que contienen clases simples Java. Para ejecutar bytecodes, la máquina virtual utiliza cargadores de clases para obtener los bytecodes del disco o de la red. Cada archivo de clases se lleva entonces a un verificador de bytecodes que se asegura de que la clase tienen un formato correcto y que no llegará a corromper la memoria cuando se ejecute. Una vez verificados los bytecodes se interpretan por un interprete.
1.6 Bibliografía
Pascal. N. Dale y D. Orshalick. McGraw-Hill. 1983.
Introducción a las Ciencias de la Computación. J.G. Brookshear. Alianza Editorial. 2a. edición.
Curso de Programación. Castro et. al. McGraw-Hill. 1993.
La Biblia de Java. Vanhelsuwé et. al. Anaya Multimedia. 1996.
Fundamentos de Algoritmia. G. Brassard y P. Bratley. Prentice-Hall. 1987.
Somos un pequeño equipo con el objetivo de estudiar crear y profundizar más en el mundo de la programación esperemos que le guste nuestro trabajo así como nuestro análisis sobre los diferentes códigos y software